Openai의 Vision 및 Text용 API를 통해 GPT-4O(Omni Model)를 사용해보기 위한 튜토리얼
MY GPT 4o API Beginning Course
1. Image( multi modal)
👉 2. Summary( Video + Audio)
3. QA( Video + Audio based chat)
이번엔 비디오와 오디오를 요약하는 실습이다.
GPT 4o API 실습1. 멀티 모달 - Video : 비디오 요약
- resource
Macintosh_Team_Interview.mp4
1.11MB
- code
*Video(@AndyHertzfeld): https://www.youtube.com/watch?v=oTtQ0l0ukvQ
*Generate shorts(@ssemble) : https://www.ssemble.com/
- code
# .env file에서 환경변수(API key)가져와서 로드하기
from dotenv import load_dotenv
load_dotenv()
# 필요한 라이브러리들 로드
from openai import OpenAI
import os
import cv2
from moviepy.editor import VideoFileClip
import base64
# OpenAI 클라이언트와 모델을 초기화
client = OpenAI()
MODEL="gpt-4o"
# 비디오 경로를 설정
VIDEO_PATH = "resource/Macintosh_Team_Interview.mp4"
# 비디오를 처리하는 함수를 정의
# 비디오의 총 프레임 수를 계산하고,
# 지정된 간격으로 프레임을 건너뛰며 이 프레임을 base64 문자열로 인코딩,
# 그리고 비디오의 오디오를 추출하여 별도의 파일로 저장.
def process_video(video_path, seconds_per_frame=2):
base64Frames = [] # base64로 인코딩된 프레임을 저장할 List
base_video_path, _ = os.path.splitext(video_path)
video = cv2.VideoCapture(video_path)
total_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = video.get(cv2.CAP_PROP_FPS)
frames_to_skip = int(fps * seconds_per_frame)
curr_frame=0
# 총 프레임 수를 확인하고, 정해진 간격으로 프레임을 건너뛰어 base64 문자열로 인코딩하여 저장
while curr_frame < total_frames - 1:
video.set(cv2.CAP_PROP_POS_FRAMES, curr_frame)
success, frame = video.read()
if not success:
break
_, buffer = cv2.imencode(".jpg", frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
curr_frame += frames_to_skip
video.release()
# 비디오의 오디오를 추출하여 별도의 파일로 저장합니다.
audio_path = f"{base_video_path}.mp3"
clip = VideoFileClip(video_path)
clip.audio.write_audiofile(audio_path, bitrate="32k")
clip.audio.close()
clip.close()
print(f"Extracted {len(base64Frames)} frames")
print(f"Extracted audio to {audio_path}")
return base64Frames, audio_path
# 위에서 정의한 함수를 사용하여 비디오 프로세스 처리
base64Frames, audio_path = process_video(VIDEO_PATH, seconds_per_frame=1)
# OpenAI API 클라이언트를 이용해서 채팅 시작
# 비디오 요약 생성 요청,반환 결과를 포함하는 response 객체를 반환
response = client.chat.completions.create(
# 응답을 생성하는데 사용될 llm모델을 지정
model=MODEL,
# 모델의 동작을 설정하는 시스템 메시지(비디오 요약을 생성하라고 지시)와
# 사용자로부터 비디오 프레임들을 '이미지 URL' 형태의 메시지로 변환하여 OpenAI 모델에 제공하기 위한 사용자 메시지 구성
messages=[
{"role": "system", "content": "You are generating a video summary. Please provide a summary of the video. Respond in Markdown."},
{"role": "user", "content": [
"These are the frames from the video.",
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames)
],
}
],
# 봇의 응답의 무작위성을 0~2 값으로 제어, 값이 낮을수록 출력이 일관적, 값이 높을수록 무작위적이고 창조적
temperature=0,
)
# 생성된 요약을 출력
print(response.choices[0].message.content)- result

GPT 4o API 실습2. 멀티 모달 - Audio : 오디오 요약
- resource
Macintosh_Team_Interview.mp3
0.10MB
- code
*Video(@AndyHertzfeld) 파일을 위 실습1 코드를 통해 생성한 파일
- code
# .env file에서 환경변수(API key)가져와서 로드하기
from dotenv import load_dotenv
load_dotenv()
# 필요한 라이브러리들 로드
from openai import OpenAI
client = OpenAI()
MODEL="gpt-4o"
audio_path = "resource/Macintosh_Team_Interview.mp3"
# 'whisper-1' 모델을 사용해서 음성 파일을 텍스트로 변환합니다.
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=open(audio_path, "rb"),
)
# 변환된 텍스트를 기반으로 요약문을 생성합니다.
# 사용자 메시지와 시스템 메시지를 함께 제공하여, 시스템 메시지가 어떤 행동을 해야하는지 AI에 지시하고, 사용자 메시지를 기반으로 그 행동을 수행합니다.
# 이 경우, 시스템 메시지는 AI에게 텍스트를 요약하라고 지시하고, 사용자 메시지는 요약할 텍스트를 제공합니다.
response = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": """You are generating a transcript summary. Create a summary of the provided transcription. Respond in Markdown."""},
{"role": "user", "content": [
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}
],
temperature=0,
)
# AI가 생성한 요약문을 출력합니다.
# temperature 매개변수가 0으로 설정되어 있으므로, 생성된 출력은 결정론적입니다.
print(response.choices[0].message.content)
- result

GPT 4o API 실습2. 멀티 모달 - Audio + Video : 통합 요약
- resource
*위 실습 예제에서 사용했던 Audio, Video 파일
- code
# .env file에서 환경변수(API key)가져와서 로드하기
from dotenv import load_dotenv
load_dotenv()
# 필요한 라이브러리들 로드
from openai import OpenAI
from C04_Summary_Video import base64Frames
from C05_Summary_Audio import transcription
client = OpenAI()
MODEL="gpt-4o"
# client.chat.completions.create는 OpenAI API를 사용하여 AI 질의를 생성하고 결과를 반환합니다.
response = client.chat.completions.create(
# 사용할 AI 모델 이름을 지정합니다.
model=MODEL,
messages=[
# 시스템 메시지를 통해 AI에게 이 행동이 무엇인지를 설명하고 지시하게 됩니다.
{"role": "system", "content":"""You are generating a video summary. Create a summary of the provided video and its transcript. Respond in Markdown"""},
# 사용자 메시지는 AI에게 인풋(input)을 제공합니다.
{"role": "user", "content": [
# 다음 문장은 비디오 프레임에 대한 설명을 제공합니다.
"These are the frames from the video.",
# 이후에 사용자가 제공하는 각 프레임(image)는 'image_url' 타입의 메시지로 제공됩니다.
# map 함수와 람다 표현식을 사용하여 각 base64Frames 항목을 이미지 URL로 변환합니다.
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, base64Frames),
# 마지막으로, 비디오의 오디오 전사본이 'text' 타입의 메시지로 제공됩니다.
{"type": "text", "text": f"The audio transcription is: {transcription.text}"}
],
}],
# temperature 매개변수는 생성된 출력의 다양성을 결정합니다. 낮은 값은 추론 결과가 좀 더 결정적(deterministic)이고 예측 가능하도록 만듭니다.
temperature=0,
)
# AI에 의해 생성된 요약 (response의 첫 번째 선택 항목)을 출력합니다.
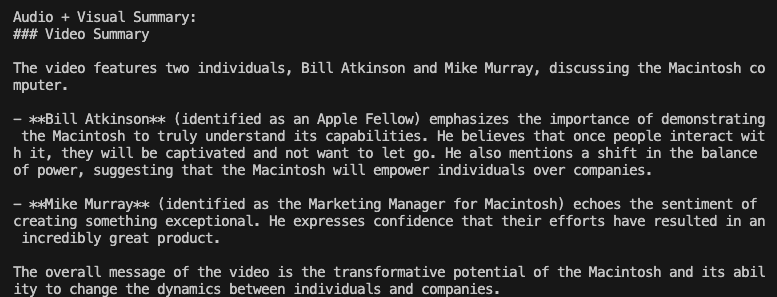
print("\\n\\nAudio + Visual Summary:\\n" + response.choices[0].message.content)
- result
'새로워지기 > 마흔의 생활코딩' 카테고리의 다른 글
| GPT4o API 리뷰 1 | 멀티모달에 대한 보편적 접근성 (0) | 2024.05.17 |
|---|---|
| LLM | GPT 4o API 실습 Beginning - 3. Video + Audio based QA (0) | 2024.05.15 |
| LLM | GPT 4o API 실습 Beginning - 1. Image( multi modal) (0) | 2024.05.15 |
| LangGraph - 실습 1. Agent Executor (0) | 2024.05.13 |
| LLM 관련, my study flow (0) | 2024.05.13 |




댓글