실습 자료 - 파이썬 증권 데이터 분석
파이썬 증권 데이터 분석
웹 스크레이핑으로 증권 데이터를 주기적으로 자동 수집, 분석, 자동 매매, 예측하는 전 과정을 파이썬으로 직접 구현한다. 그 과정에서 금융 데이터 처리 기본 라이브러리(팬더스)부터 주가 예
www.aladin.co.kr
실습 예제 중, 실제 운용 중인 포트폴리오 또는 종목을 적용해 본 산출물 정리
주요 실습 결과 01. 샤프 지수
샤프 지수가 가르키는 최적화(max_sharpe, min_risk) 포트폴리오 위에 내가 보유한(my_position) 포트폴리오를 찍어봤다.
(*책 p.254 ~ p.267 & 저자의 깃헙 쏘스 )
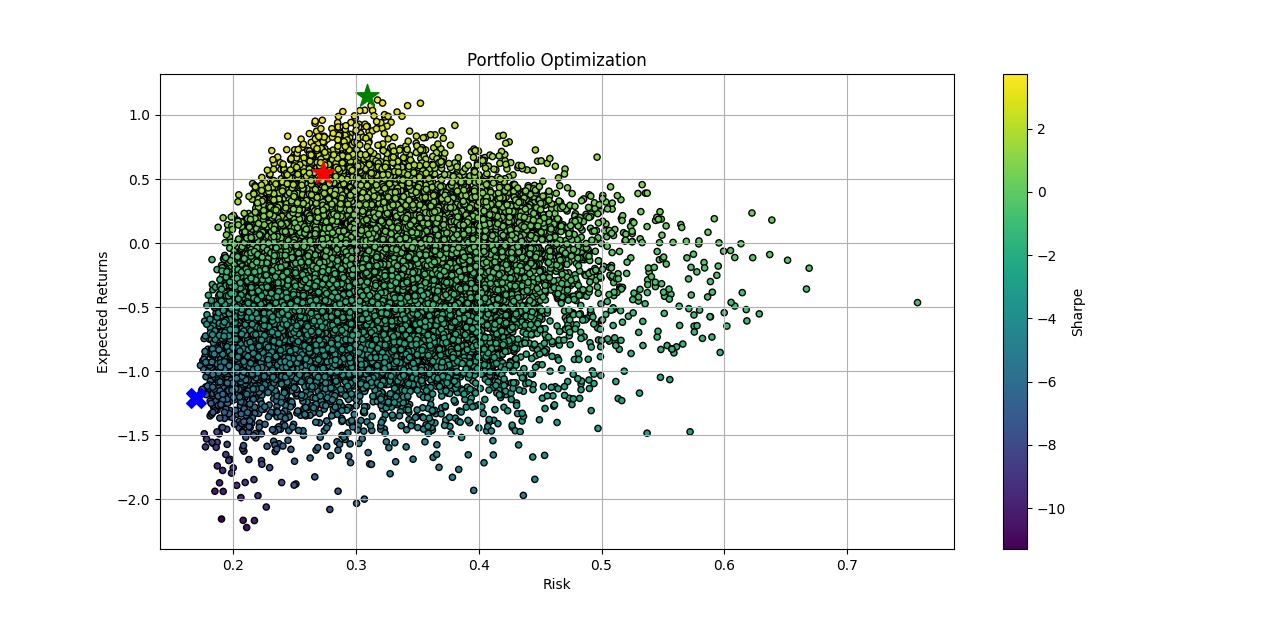
* 코드 커스텀 리뷰 :
아.. 실습 결과 그래프를 보니, 저 위에 내 포폴은 어디쯤 위치라고 있을까? 하는 궁금증이 생겼다. 그런데 막상 넣고는 싶은데.. 어떻게 시작해야 할지 막막.했다. 일단 보유 종목을 변수에 담아 보자-라고 생각했다. 처음엔 list에 담았다가 한참 고생하고 ㅋㅋㅋ 더미 데이터에 append한 결과가 뭉개지는? 결과를 확인한 후 ㅋㅋㅋ 뒤늦게 np array로 옮겨 담았다.
np array로 담고보니 가닥이 잡히기 시작했다. 내 포폴의 수익률과 리스트를 구해서, 랜덤으로 생성했던 20,000개의 경우의 수 포폴 맨 뒤에 담았다. 마지막으로 맨 뒤에 담았던 레코드(나의 포폴)를 plt그래프 그리는 코드에 추가했다. 완성
# my 포트폴리오
my_portfolio = [0.497085, 0.286782, 0.076786, 0.058613, 0.040487, 0.040247]
my_weights = np.array(my_portfolio)
# 포트폴리오 전체 수익률
my_returns = np.dot(my_weights, annual_ret)
# 포트폴리오 전체 리스크
my_risk = np.sqrt(np.dot(my_weights.T, np.dot(annual_cov, my_weights)))
# 랜덤 포폴에 나의 포폴추가
port_weights.append(my_weights)
port_ret.append(my_returns)
port_risk.append(my_risk)
sharpe_ratio.append(my_returns/my_risk)
# 나의 포트폴리오 행 지정 마커
plt.scatter(x=my_position['Risk'], y=my_position['Returns'], c='r', marker='*', s=300)
*리뷰 : 오예~ 커스텀을 했다~ 는 만족감은 오래가지 않았다. 커스텀 쓸모에 대해 생각이 그리 좋지 않았다. 포트폴리오 비율만으로는 정보가 부족하다는 생각이 들었다. 매수 비중이 아무리 탁월해도 각 종목별 매수 포지션에 따라 결과가 판이하게 달라질 것 같다는 생각이 들었다. 포폴을 만들기 전에 개별 종목에 대한 타당성, 매수 포지션 등에 대한 검증을 한 후 최종 단계에서 샤프 지수를 활용하면 쓸모가 많이 개선될 것 같다는 생각이 들었다. 다른 지표들을 공부하고 다시 돌아올 것 같은 찐한 예감이 든다. 그때는 지금의 샤프보다 더 날카로울 것 같다는 기대를 하며 오늘은 여기서 마침표.
주요 실습 결과 02. bollinger_TrendFollow
이번 파이썬 책을 통해 처음 알게 된 볼린저 밴드는 다른 지표들과 다르게? 아직까지도 현업에서 많이 사용되고 있는 지표인 것 같다. 주식 변동폭의 상하중 표준 편차를 구한 뒤 그 구간안에서의 이동에 대한 확률적 추세를 파악하는데 활용되고 있는 방법론이다.
(*책 p.275 ~ p.281 & 저자의 깃헙 쏘스 )

* 리뷰 : 볼린저 밴드를 종목에 대한 매수 매도 타이밍을 잡기 위한 자동화 트레이딩 툴로 사용하는 경우가 많은 것 같다. 개인적으로 볼린저 밴드 지표는 단일 종목에 대한 매수 타이밍으로 활용하기보다 주가 전체에 대한 장세를 파악하는데 더 유용하게 쓰이지 않을까 생각한다. 갑짜기 왠 장세? 라고 할 수 있겠지만... 주린이로서 이것 저것 구글링해본 결과 주식에는 계절과 같은 장세가 있다는 걸 알게되었다. 금융장세>실적장세>역금융장세>역실적장세 가 마치 사계절처럼 순환하는 것이다. 바로 이 장세를 파악하는데는 아주 탁월할 것 같다는 생각이다.
개인적으로.. 빅? 데이터를 다루는데 있어서 가장 중요한 것은 알고리즘보다 데이터 전처리이다. 그리고 이 전처리에는 자르고 나누고 거르고 하는 다양한 작업들이 있겠지만 그 중요한 것 중에 빠뜨리지 말아야할 것이 분류이다. 수~~~ 많은 증시관련 데이터에 대한 가장 큰? 분류 중 하나가 장세를 파악하는 것인데.. 이때 볼린저 밴드가 아주 요긴하게 쓰일 수 있을 것 같다.
주요 실습 결과 03. RNN 순환신경망
텐서플로우에 있는 RNN(recurrent neural network 순환신경망)을 적용한 예측값이다.
(*책 p.432 ~ p.446 & 저자의 깃헙 쏘스 )

* 리뷰 : 코드를 이해하고 작성하는 것보다 환경설정에서 가장 애를 먹었다. 환경설정 내용은 맨 아래 링크 참조... 실제 값과 예측 값의 추세가 비슷하긴 하지만 매번 돌릴때마다 & 기간 또는 학습 횟수를 변경할때마다 결과에 큰 차이를 보이고 있다. 아무래도 학습용 기본 내용만으로 구현된 예제라서 그런것 같다. 아래 예제는 여러번 돌리다 그나마 유사한 결과를 저장해놓은 이미지이다. 참고로 기간은 작년 3월(코로나 급락)부터 작성일 전일 까지로 설정했고 기간이 줄어든 만큼 학습 횟수도 비례해서 줄여주었다.
**텐서플로우 설치 normalstory.tistory.com/entry/a-1?category=977100
파이썬 3.8 64bit에 텐서플로우 2.2 설치(feat. 아나콘다)
* 개발 환경 : 샤오미 레드미 노트북 64비트, RYZEN 4000 시리즈 7. 윈도우 10 64 비트 책과 달리, 내 컴퓨터에서는 pip install tensorflow 가 안된다. 파이썬 까지는 잘됐었는데... 흑흑... pip Install Error:..
normalstory.tistory.com
주요 실습 결과 04. LSTM 순환신경망
텐서플로우에 있는 LSTM(Long Short-Term Memory models)을 적용한 예측값이다.
책에 있는 내용이 맛보기 실습용인 까닭에 예측결과에 정확도와 균일성이 조금 아쉬웠다. 그래서 구글링의 통해 다른 예제를 찾기 시작했다. 최근 업데이트된 텐서플로우2, 텐서보드, 케라스를 활용해서 주식시장(종목)에 대한 가격을 예측하는 코드를 발견했다. 아래 이미지는 예제를 실행한 결과이다. 종목은 아마존이고 파란색이 실제 값 빨간색이 예측값이다.

위 예제는 야후 파이낸스 api를 사용한 지표이다. 하지만 위와 같이 야후 파이낸스 api를 활용한 코드의 경우 국내 주식에는 대응하기 애매한 부분이 많다. 그래서 코드의 일부를 네이버 증권에의 내용을 스크래핑해서 뿌려주도록 수정해보았다. 예시는 삼성전자. 삼성전자가 이전에 분할도 했고 작년에 코로나로 인한 급락과 급등 그리고 2월 약세 등을 가장 드라마틱하게 경험하고 있어서 가장 적절하다고 판단했다.

위 결과는 기본의 1/100 수준이다. 디폴트인 EPOCHS를 500으로 하면... 내 노트북으로.. 4~5시간이 걸린다... 참고로 보유 노트북은.. 샤오미 RedmiBook 13인치.. and 그래픽카드가 없다..
앞으로 한달 정도 더 공부해보고... 정말 컴퓨터 때문에 못해먹겠네 ㅋㅋㅋ 정도의 실력을 갖추게 된다면.. 그때가서 GPU 달린 데스트탑 하나를 장만할지 말지 고려할 예정이다.. 일단 학습 단위를 줄여서 학습 고고 ~
* RNN과 LSTM을 비교해서 설명하고 있는 참고 포스트 ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
RNN과 LSTM을 이해해보자! · ratsgo's blog
이번 포스팅에서는 Recurrent Neural Networks(RNN)과 RNN의 일종인 Long Short-Term Memory models(LSTM)에 대해 알아보도록 하겠습니다. 우선 두 알고리즘의 개요를 간략히 언급한 뒤 foward, backward compute pass를 천천
ratsgo.github.io
* LSTM과 관련된 논문 scienceon.kisti.re.kr/commons/util/originalView.do?cn=JAKO201819355173173&oCn=JAKO201819355173173&dbt=JAKO&journal=NJOU00564564
원문보기 - ScienceON
이 원문은 ScienceON에서 제공하고 있습니다.
scienceon.kisti.re.kr
요약 : 단방향 LSTM 순 환신경망을 사용하였을 때보다 양방향 LSTM 순환신경 망 모델이 향상된 성능을 갖는 학습 모델로 도출되었 다
'새로워지기 > 마흔의 생활코딩' 카테고리의 다른 글
| 정규식 코드, 더 이상 구글링 복붙하지 않기 위한 40분 투자! (0) | 2021.03.01 |
|---|---|
| 파이썬 3.8 64bit에 텐서플로우 2.2 설치(feat. 아나콘다) (0) | 2021.02.24 |
| [마흔에 파이썬] 배우는 여정 (0) | 2021.02.18 |
| 마흔에 입문하며 소셜 이용현황 리뷰 (0) | 2021.02.06 |
| [마흔에 파이썬] 공부를 시작한 계기 (0) | 2021.02.03 |

댓글