이번 포스팅의 내용은 금주 학습 과정 중 특정 키워드를 선정해서 관련 내용을 리서치하고 토론했던 내용에 대한 기록이다.
무심코 지나쳤지만, 알아두면 좋은, 이론적인 부분들에 대해 상세한 리서치를 하고 관련 내용을 취합하는 과정에서 그치지 않고 필요할때복붙?참고하기 위해 각각에 해당하는 실습 코드들도 함께 정리해보았다.
-update: 출처와 이름을 밝히더라도 팀원 분들께서 참여하신 부분에 대한 내용은 이 블로그에 포스팅하는 것은 적절하지 않을 것이라는 뒤늦은 판단으로 관련 내용은 모두 삭제하였습니다.
주제 1.
데이터의 차원이 증가함에 따라 나타나는 '차원의 저주 (The curse of dimensionality)' 현상에 대해 조사해 보고, 해당 현상의 발생원인과 또 그에 따른 해결방법은 무엇이 있는지 토의해보자. [ 주제 : 데이터와 차원 ]
(중략)
1) 학술적이고 이론적인 이해도 좋지만 관련 내용이 적용된 코드와 그 결과에 대해 조금 더 구체적으로 알아보면 좋을 것 같다.
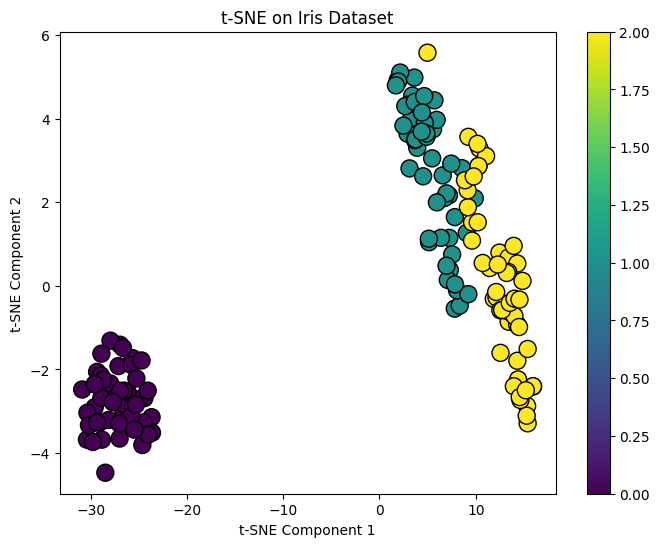
(1) Iris 데이터셋 기반 예시
- PCA 예시 코드

- t-SNE 예시 코드
(2) digits 데이터셋 기반 예시

- PCA 예시 코드
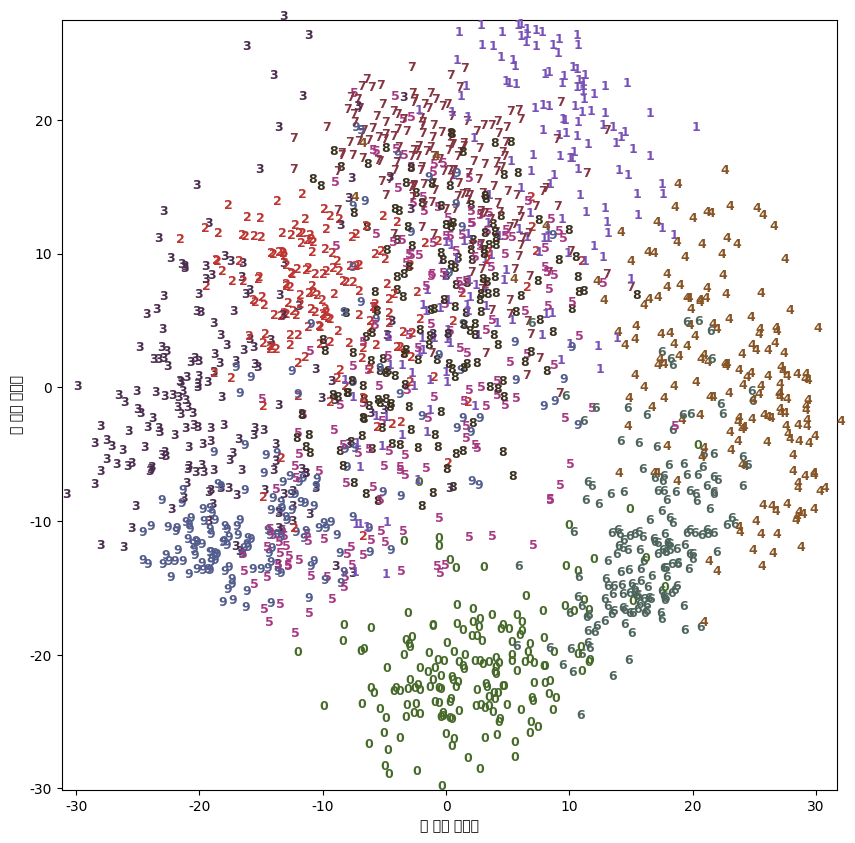
- t-SNE 예시 코드

2) 리서치 레퍼런스 글에서 설명하고 있는 내용만 보면 원각 각 기법들의 용도가 명확히 달라 보였는데.. (실제 코드의 출력 결과를 보니 개인적으로-엔터6, 단순 비교로는 t-SNE 기법이 PCA보다 더 우월?해보이는데??.. 사실, 테이블 리서치 내용들이 잘 납득이 가질 않는다.) 조금 더 구체적으로 ‘이럴땐 이 기법, 저럴땐 저 기법'과 같이 조금 더 명확하게 용도를 내용을 정리해보면 좋을 것 같다.
3. 결론
케이스 바이 케이스로 PCA와 t-SNE의 선택 기준을 정리해보자
1) 데이터의 특성:
- 고차원 데이터가 직선적 구조를 가지는 경우: PCA
- 고차원 데이터가 비직선적 구조를 가지는 경우: t-SNE
2) 속도와 규모:
- 대규모 데이터에 대해 빠른 처리가 필요한 경우: PCA
- 데이터가 비교적 적고 국소적 구조가 중요한 경우: t-SNE
3) 목적:
- 특징 추출 및 데이터 압축이 필요한 경우: PCA
- 데이터 시각화 및 패턴 발견이 필요한 경우: t-SNE
4) 실무 예제
- PCA 사용 사례:
고객 데이터의 주요 특성을 분석하여 중요한 변수를 찾고, 차원을 축소하여 모델의 성능을 향상시킵니다.
유전자 데이터에서 중요한 유전자 패턴을 추출하고, 데이터의 잡음을 줄여 분석합니다.
- t-SNE 사용 사례:
이미지 데이터나 텍스트 데이터의 임베딩을 2차원으로 축소하여 유사한 이미지나 문서가 어떻게 클러스터링되는지 시각화합니다. 마케팅 캠페인에서 고객의 행동 패턴을 시각화하여 유사한 행동을 보이는 고객 군을 식별합니다. 이 두 기법은 서로 보완적인 역할을 할 수 있습니다. 예를 들어, 먼저 PCA로 차원을 어느 정도 축소한 후, t-SNE를 적용하여 시각화하는 방법도 실무에서 사용됩니다.
문제 2.
파이썬 라이브러리 중 하나인 'Numpy'의 특징에 대해 서술하고, Numpy의 등장으로 더욱 편리해진 작업들은 무엇이 있는지 조사해보자. [ 주제 : 파이썬 ]1. 자료조사
1. Numpy 설명
(중략..)
2. 토의내용
1) 항목별로 정리되어 이해는 되지만 뭔가 너무 개념적으로만 접근한 것은 아닌가 생각된다. 조금 더 실질적인 이해를 위해 위 사례들이 반영된 코드 예시를 찾아보면 좋을 것 같다.
(1)효율적인 다차원 배열 처리
--> 결과,
Array shape: (3, 3)
Modified array:
[[ 1 2 3]
[ 4 5 10]
[ 7 8 9]]
(2) 고성능 수치 계산
--> 결과, [0.01176252 0.59470493 0.83800347 0.36904421 0.02989509]
(3) 데이터 전처리 및 분석
--> 결과,
Mean: -0.055785869551972574
Standard Deviation: 0.9666896586679969
First 5 normalized data points: [-1.22099914 0.03545876 -2.18956188 0.5683409 -0.61175484]
(4) 과학 계산 및 시뮬레이션
--> 결과, Solution x: [2. 3.]
(5) 데이터 시각화와 상호 운용성
--> 결과,
(6) 머신러닝과 데이터 과학
--> 결과, Predictions: [1.21 1.635 2.06 2.485 2.91 ]
2) NumPy가 등장하기 전과 후를 비교해보면 어떨까? NumPy의 용도/쓰임새에 대해 조금 더 직관적으로 이해할 수 있을 것 같다. 관련 코드도 정리해보자
과거에 NumPy가 등장하기 전에는, 대규모 데이터 처리와 수치 연산을 Python의 기본 데이터 구조와 반복문을 사용하여 수행해야 했습니다. 이는 특히 대규모 데이터셋이나 복잡한 수치 계산에서 매우 비효율적이었습니다. 아래는 NumPy가 없었던 시절의 예시 코드를 보여줍니다.
실습 코드 1. 대규모 행렬 연산 : 속도의 차이가 현저히 나고 코드도 훨씬 직관적으로 개선되었다.
- 과거
--> 결과, 처리 속도 = 2m 9.1s
- numpy 적용 후
--> 결과, 처리 속도 = 0m 0s
실습 코드 2. 이미지 처리 : 코드의 길이도 줄어들고 속도도 빨라졌다
- 과거
--> 결과, 처리 속도 = 1m 1s
- numpy 적용 후
--> 결과, 처리 속도 = 0m 7s


좌-적용 전, 우-적용 후 (이미지 출처: 하늘 적운 분위기 클라우드 - Pixabay의 무료 이미지 )
3. 결론
(1) 앞서 코드 예제를 통해 확연한 차이를 알게 되었다. 마지막으로 기능 관점의 코드가 아닌 실무와 관련된 예제 코드를 실습해보면서 마무리하도록 하자.
[ 사례 ] 제품 판매 분석 예 : 여러 제품의 월별 판매량과 수익을 분석하여 어떤 제품이 가장 이익이 많은지, 어떤 달에 판매가 가장 좋은지 파악할 수 있다. (출처 : 넘파이를 활용한 실제 사례 예시 )
- 샘플 데이터 세팅
- 총 판매량 계산
--> 결과, 총 판매량: [550 480 390]
- 각 제품별 총 이익 계산
--> 결과, 총 이익: [7650 8500 9575 9425]
- 가장 높은 판매량을 기록한 월 찾기
--> 결과, 가장 높은 판매량을 기록한 월: 3월
- 가장 이익이 높은 제품 찾기
--> 결과, 가장 이익이 높은 제품: 제품 3
GitHub - normalstory/2024AI_CoachingStudy
Contribute to normalstory/2024AI_CoachingStudy development by creating an account on GitHub.
github.com
'새로워지기 > 사이드 프로젝트' 카테고리의 다른 글
| LET’s AI 2024 코칭 스터디 - 3주차, 팀 미션 (1) | 2024.06.11 |
|---|---|
| 데이터 분석 및 시각화 실습 - 기상 자료(서울 날씨) (0) | 2024.06.08 |
| 시각 지능 | 신호등 신호 분류기( feat. yolo v8, roboflow 데이터 증강) (0) | 2023.10.03 |
| [from.designer] Psychology Study (0) | 2023.07.16 |
| A4C on my own | 커피 캡슐 분리수거 캡 제작기( ing..) (0) | 2023.04.27 |




댓글