모두연에서 진행하는 AI 코칭 스터디를 통해 정말 오래된 기억들을 새록새록 복기할 수 있는 기회를 얻고 있다. 더불어 좋은 팀원들을 만나 좋은 자료들을 공수 받아 관련 내용을 정리할 수 있는 기회도 획득! 했다. (보충자료 : AI 2024 코칭스터디 팀미션(로롱코칭_6팀). by_@박문지)
초등학교때, 고등학교때, 대학교 그리고 사회생활을 하면서 읽는 '어린 왕자'가 각기 다른 감동을 선사하듯 최근 복기하고 있는 파이썬,맷플롯립, 판다스 또한 -물론 감동? 까진아니어도 ㅋ 그정도 변태는 아니다ㅋ- 새로운 느낌이다.
암튼, 이번 실습을 통해 현장 데이터를 수집-정제-리뷰-전처리-인사이트 도출-시각화 등 반복되는 패턴 또는 코드들을 정리해두고 나중에 필요할때 Ctrl+C, Ctrl+V로 요기나게 재활용할 예정이다. 물론.. GPT의 속도가 더 빠르겠지만 말이다 ㅋㅋㅋ
데이터 수집
서울 기온 데이터(csv, https://data.kma.go.kr/stcs/grnd/grndTaList.do?pgmNo=70 )
기상자료개방포털[기후통계분석:통계분석:기온분석]
중부(26) 서울경기: 서울(108), 인천(112), 수원(119), 강화(201), 양평(202), 이천(203) 강원영동: 속초(90), 강릉(105), 태백(216) 강원영서: 철원(95), 대관령(100), 춘천(101), 원주(114), 인제(211), 홍천(212) 충북:
data.kma.go.kr
패키지 추가하기
# 라이브러리 임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
데이터 로드, 전처리
# 데이터 로드
df = pd.read_csv('data/weather_seoul_1980to2024.csv')
df.head()Error:
* UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb1 in position 0: invalid start byte
--> 수집한 csv파일을 메모장에서 열어서 인코딩 종류를 utf8로 지정후 다른이름으로 저장해서 사용
* ParserError: Error tokenizing data. C error: Expected 1 fields in line 8, saw 5
--> CSV 포맷이 맞지 않는 경우. 즉 , (콤마)로 구분되어 있지 않아서...csv 파일에서 머릿글 영역을 삭제 후 저장해서 사용
* NameError: name 'pd' is not defined
-->\t 가 들어가 있음...메모장에서 문자열 바꾸기 기능을 이용해서 \t 을 삭제함.

한글 폰트 설정
matplotlib은 ‘sans-erif’를 default로 하기 때문에 한글 지원을 하지 않는다. 그래서 표의 타이틀, 컬럼명, 라벨 그리고 범례가 한글인 경우 깨져서 출력된다. 이럴땐 matplotlib.rc 를 통해 폰트를 재설정하고 그 결과를 확인한다.
# 현재 폰트 확인 : ['sans-serif']
import matplotlib
matplotlib.rcParams['font.family']# 한글 깨짐 개선 for Mac
import matplotlib.pyplot as plt
from matplotlib import rc
rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False
# 한글 깨짐 개선 for Win
import matplotlib
import matplotlib.font_manager as fm
font_name = fm.FontProperties(fname = 'C:/Windows/Fonts/malgun.ttf').get_name()
matplotlib.rc('font', family = font_name)
matplotlib.rcParams['axes.unicode_minus'] = False
# 바뀐 폰트 확인 : ['AppleGothic']
import matplotlib
matplotlib.rcParams['font.family']
데이터 리뷰
# 최근 데이터 살펴보기(*지점=서울)
df.tail()
#데이터 요약 통계 정보
df.describe()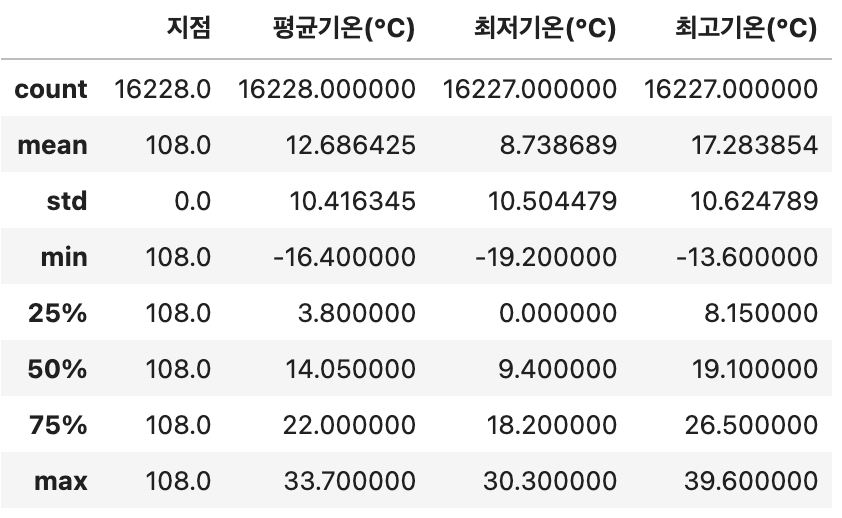
# 데이터 일반 정보 : 행16288, 컬럼5, 결측(3,4컬럼이 0,1,2컬럼 수와 다름)
df.info()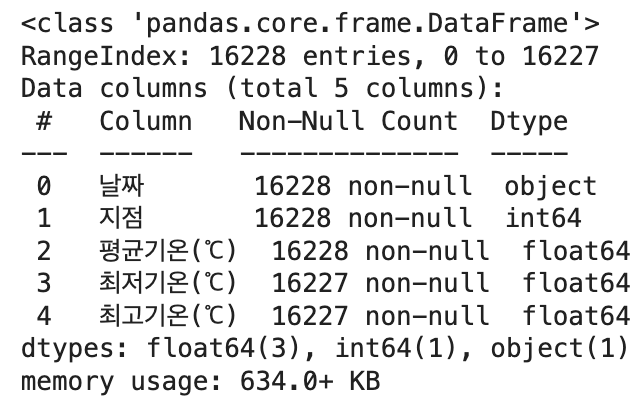
전처리
컬럼명 조정
df.columns
df.columns = ['날짜', '지점', '평균기온', '최저기온', '최고기온']
df.columns
df.head()
결측치 확인
#isnull()
df.isnull().sum()
# 최저기온 결측치인 날짜 찾음 - 태풍
# https://imnews.imbc.com/replay/2022/nw1400/article/6396123_35722.html
# 하지만.. 장비과 관련된 별도의 내용을 찾을 수 없었다.
cond = df['최저기온'].isnull()
df[cond]
# 최고기온 결측치인 날짜 찾음 - 지진? 오히려.. 15일 포항 지진인데?
# 역시, 장비 운용과 관련된 별도의 내용을 찾을 수 없었다.
cond = df['최고기온'].isnull()
df[cond]
df.info()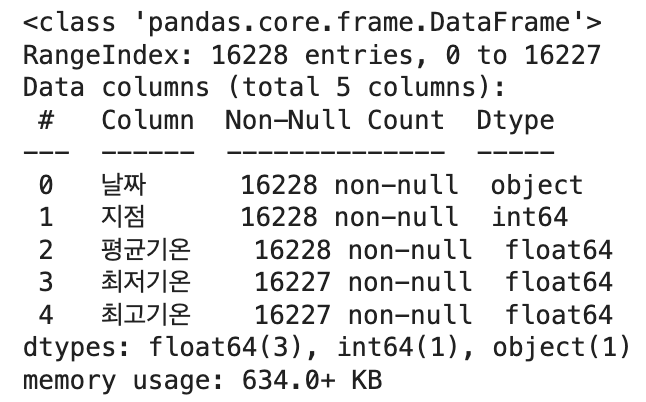
# 결측치 처리
df.dropna(inplace=True)
날짜 형 변환
# 날짜 형 변환(inplace=True 옵션이 없는 경우)
# object to datetime pandas - https://pandas.pydata.org/docs/reference/api/pandas.to_datetime.html
df['날짜'] = pd.to_datetime(df['날짜'])
df.info()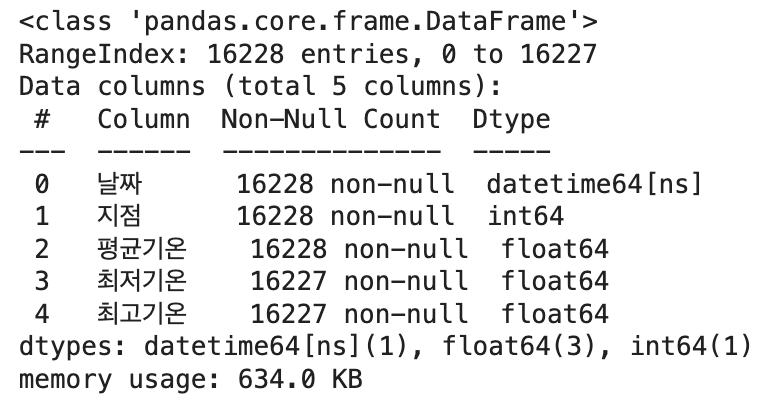
df.head()
# 년,월,일 컬럼 파생
df['년'] = df['날짜'].dt.year
df['월'] = df['날짜'].dt.month
df['일'] = df['날짜'].dt.day
df.info()
df.head()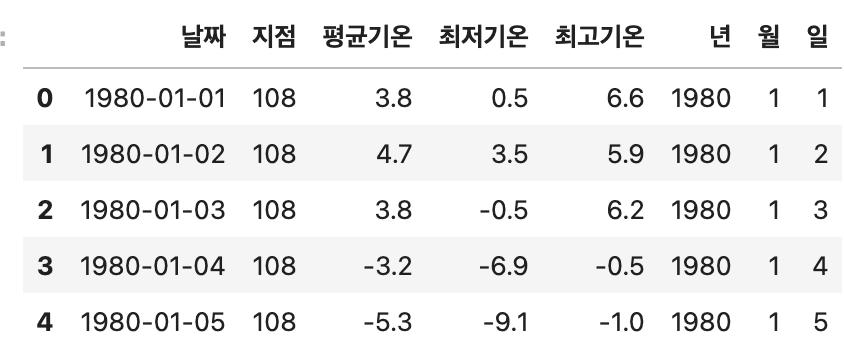
분석
데이터 테이블에서 특정 조건에 맞는 요소들을 추출하여 데이터 테이블을 재구성한다. 그리고 특정 요소들을 그래프를 통해 서로 비교해볼 수 있도록 한다.
가장 더웠던 날
#최고 더운 날은? (최고기온)
hottestDayList = df.sort_values(by='최고기온',ascending=False)
hottestDayList.head()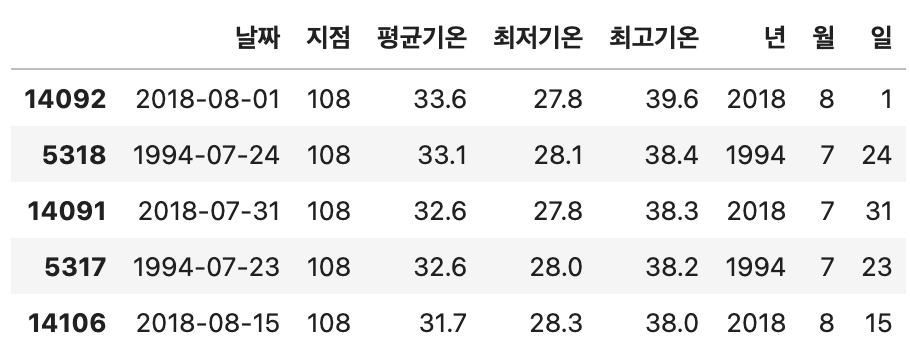
hottestDayList.iloc[0] # 0번째 행 = 가장 뜨거운 날
hottestDayList.iloc[0,0] # 0번째 행과 렬 = 가장 뜨거운 날, 날짜 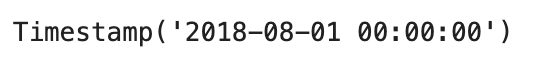
#날짜 타입을 문자열로 출력
df.iloc[0,0].date()
df.iloc[0,0].strftime('%Y-%m-%d')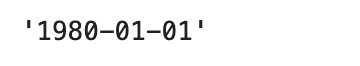
hottestDayList.iloc[0,4] # 가장 뜨거운 날, 온도 
# 서울에서 가장 더웠던 날 출력
hotday = hottestDayList.iloc[0,0].strftime('%Y-%m-%d')
temp = hottestDayList.iloc[0,4]
print(f'서울에서 가장 더웠던 날은? {hotday} : {temp}도')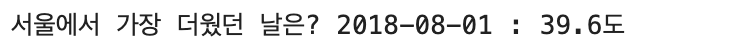
새해 첫날 온도 그래프
# 1980년 이후의 1월 1일 데이터만 추출
cond = (df['년'] >=1980) & (df['월']==1) & (df['일']==1)
birth_df = df[cond]
birth_df.head()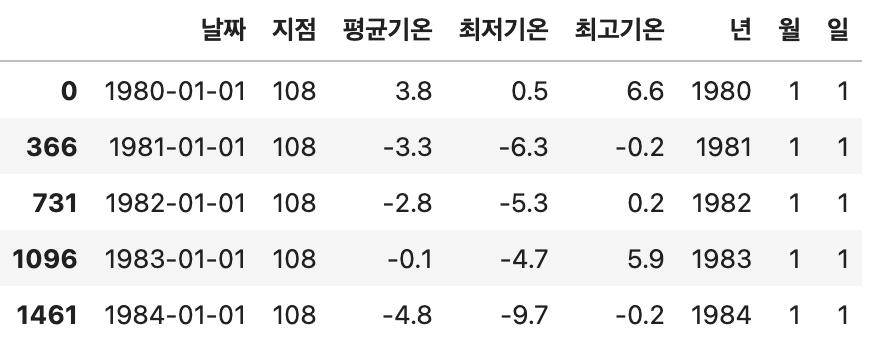
# 필요한 컬럼만 추출(날짜, 평균기온)
col_lst = ['날짜','평균기온']
birth_df = birth_df[col_lst]
birth_df.head()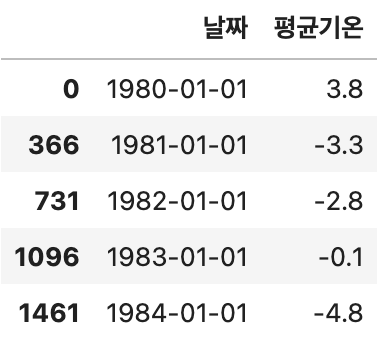
## 폰트 설정 및
plt.rc('font', family='AppleGothic') #맥
# plt.rc('font', family='NanumSquare') #나눔 글꼴로 설정
# plt.rc('font', family='Malgun Gothic') #맑은 고딕으로 설정
# 마이너스 부호 설정
plt.rcParams['axes.unicode_minus'] = False #부호# 새해 첫 날 기온 데이터
day = birth_df['날짜'].values
temp_avg = birth_df['평균기온'].values
plt.plot(day,temp_avg)
plt.xlabel('날짜')
plt.ylabel('평균기온')
plt.title('새해 첫 날 기온 데이터(1/1)')
plt.axhline(y=0, color='orange', linestyle='--')
plt.show()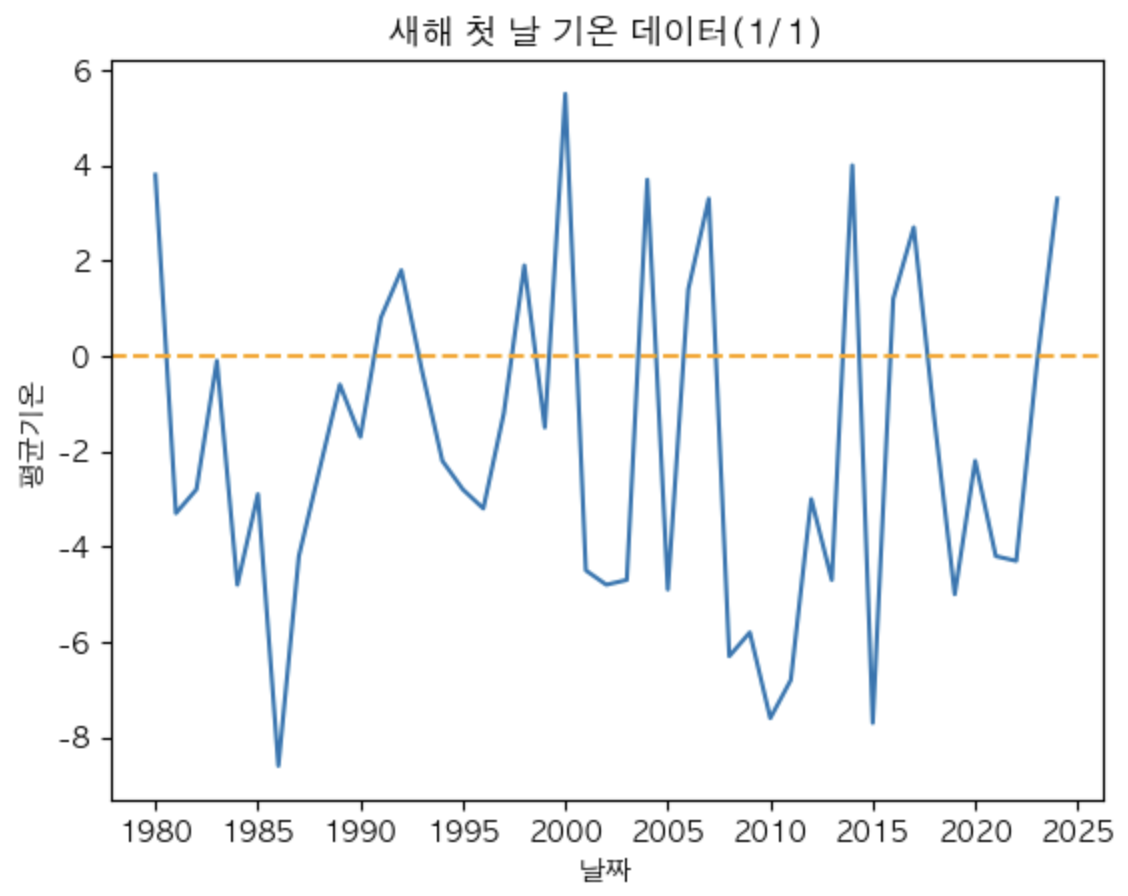
크리스마스 최고/최저 기온 추이
# 데이터 내, 크리스마스에 해당하는 모든 데이터 추출
cond = (df['월']==12) & (df['일']==25)
chris_df = df[cond]
chris_df.head()
x = chris_df['날짜'].values
y1 = chris_df['최저기온'].values
y2 = chris_df['최고기온'].values
plt.plot(x,y1,label='최저기온',color='b')
plt.plot(x,y2,label='최고기온',color='r')
plt.title('크리스마스 최고/최저 기온')
plt.xlabel('년도')
plt.ylabel('기온')
plt.legend() #범례
plt.show()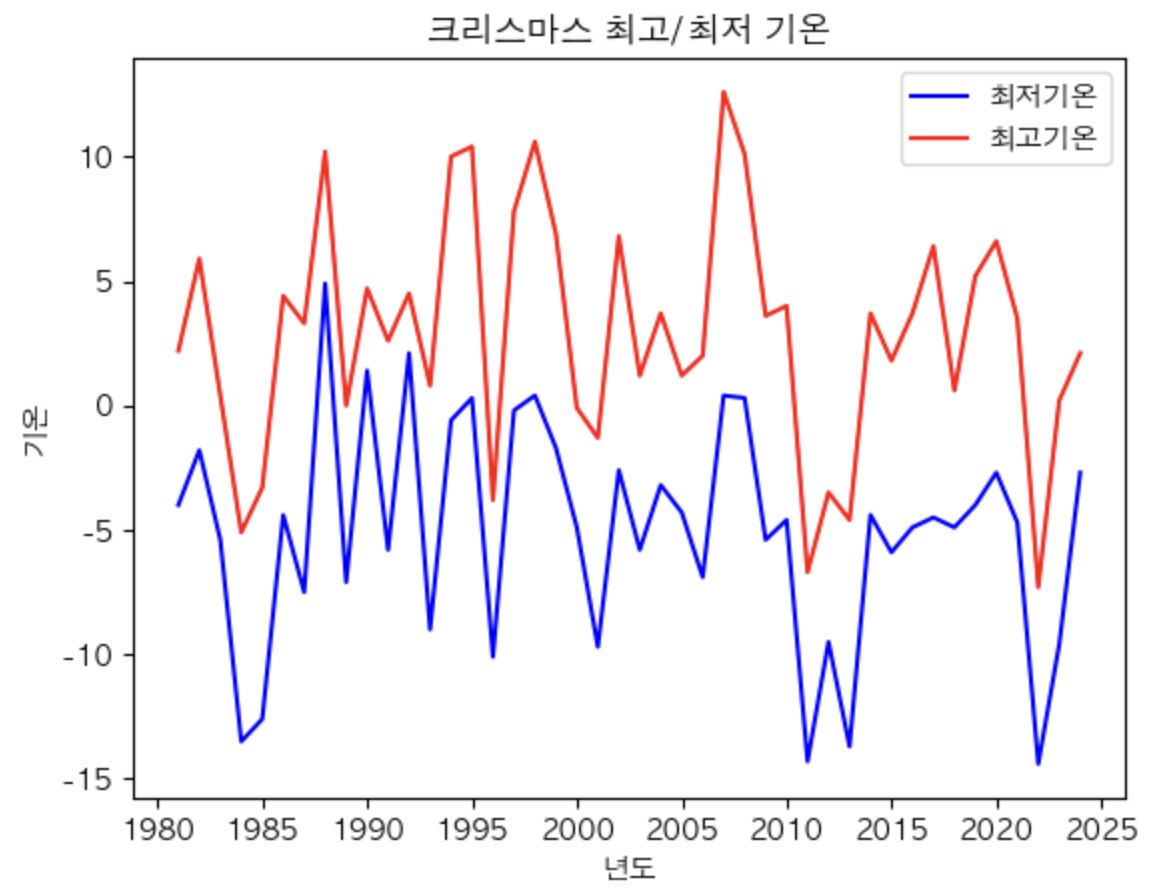
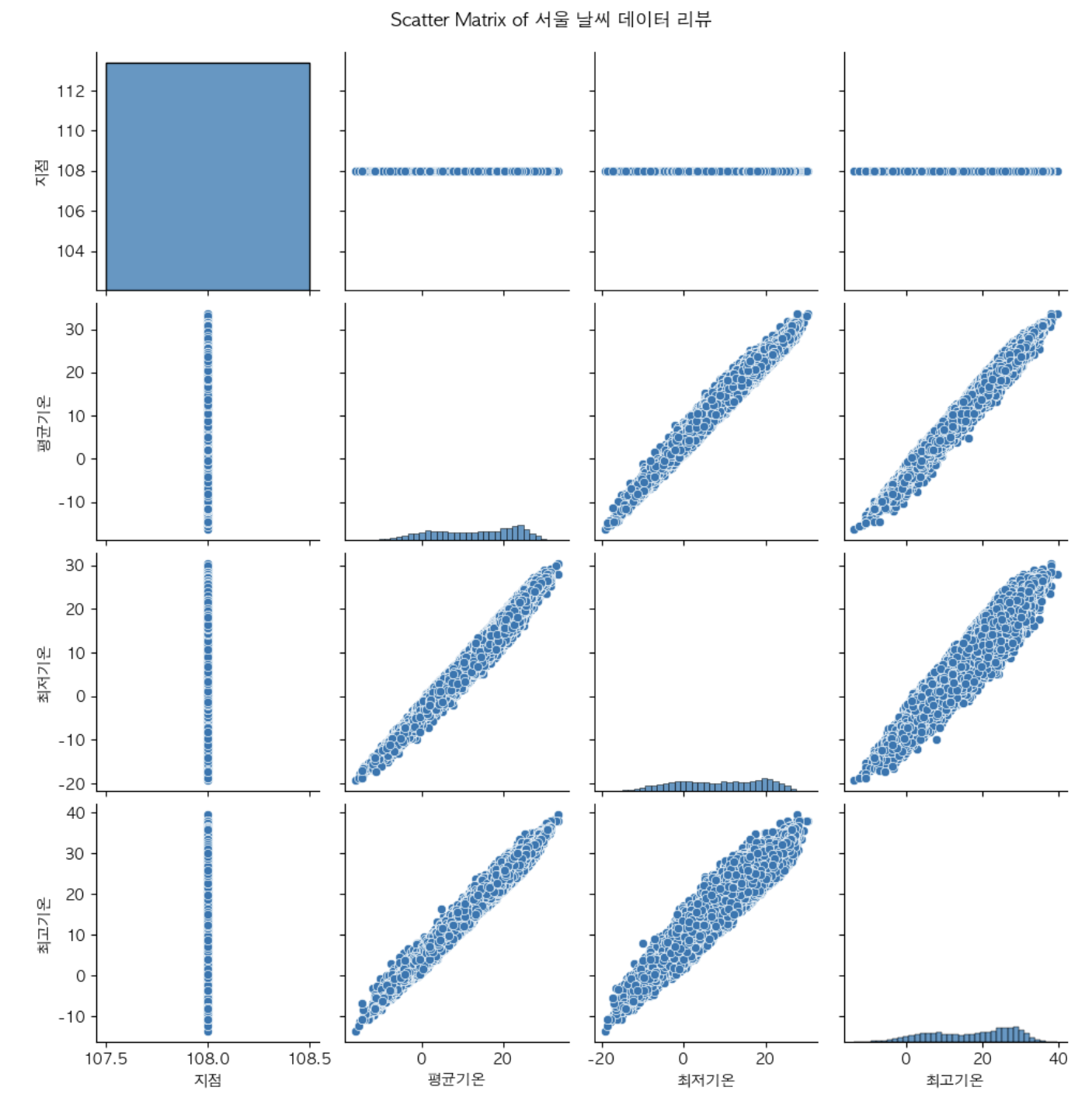
산점도 행렬 (scatterplot matrix)
여러개의 연속형 변수에 대해서 각 각 쌍을 이루어서 산점도를 그려서 한꺼번에 변수 간 관계 확인
# 분석에 사용할만한? 주요 수치 데이터 선택(*지점=서울)
selected_columns = ['날짜', '지점', '평균기온', '최저기온', '최고기온']
reviewGraph_selected = df[selected_columns]
# Scatter matrix 그리기
sns.pairplot(reviewGraph_selected)
plt.suptitle('Scatter Matrix of 서울 날씨 데이터 리뷰', y=1.02) # 제목 추가
plt.show()
히스토그램 - 서울 최고 기온
#matplotlib의 hist() 사용 - 최고기온 기준
x = df['최고기온']
plt.hist(x)
plt.show()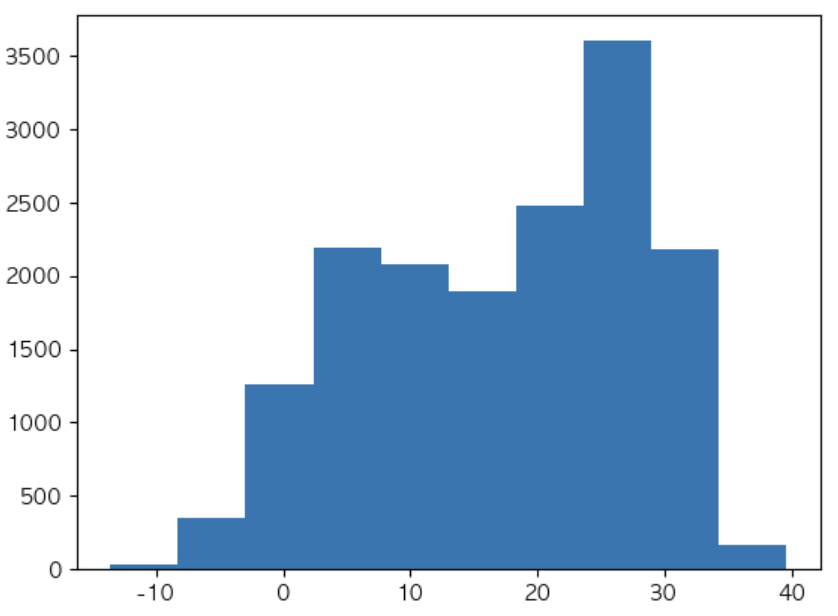
#수치형 피처의 경우 'bins' 조절을 적절하게....
df['최고기온'].hist(bins=20)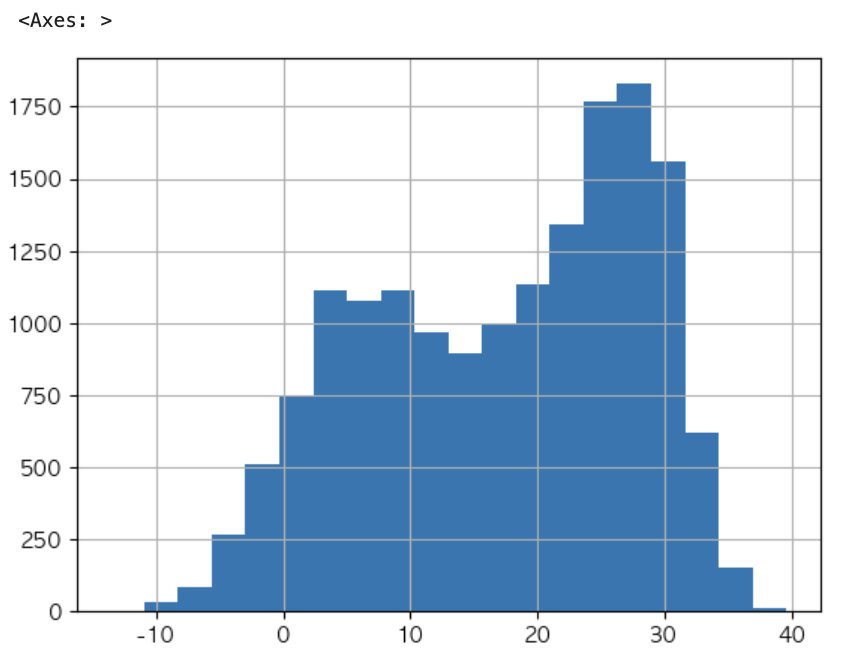
df['최고기온'].hist(bins=100)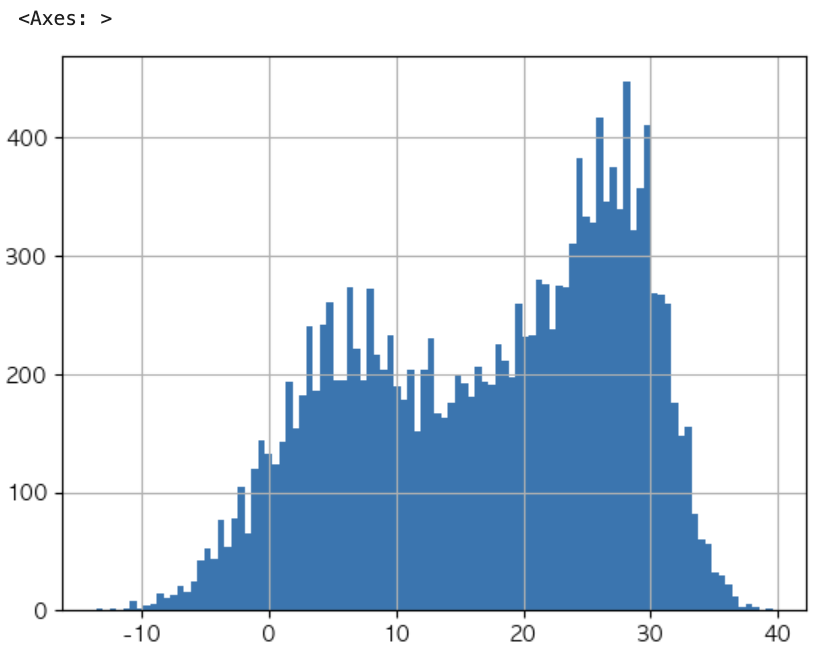
히스토그램 - 2월과 8월 서울의 최고 기온 비교하기
# 봄(2월) 데이터만 추출
feb_df = df[df['월']==2]
feb_df.head()
# 가을(8월) 데이터만 추출
aug_df = df[df['월']==8]
aug_df.head()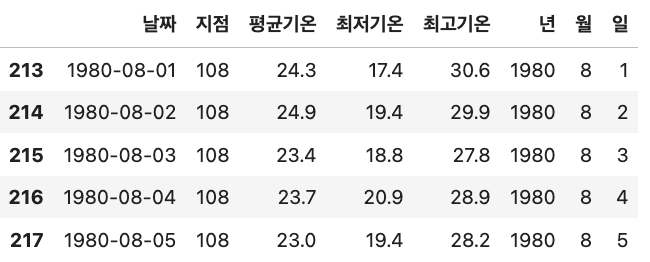
# 히스토그램 시각화
x1 = aug_df['최고기온']
x2 = feb_df['최고기온']
plt.hist(x1,bins=100,color='r',label='aug')
plt.hist(x2,bins=100,color='b',label='feb')
plt.legend()
plt.show()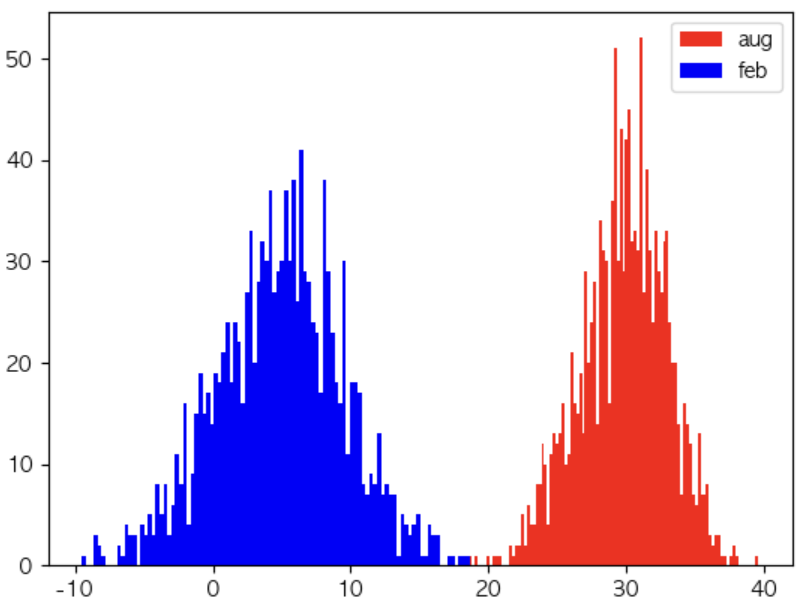
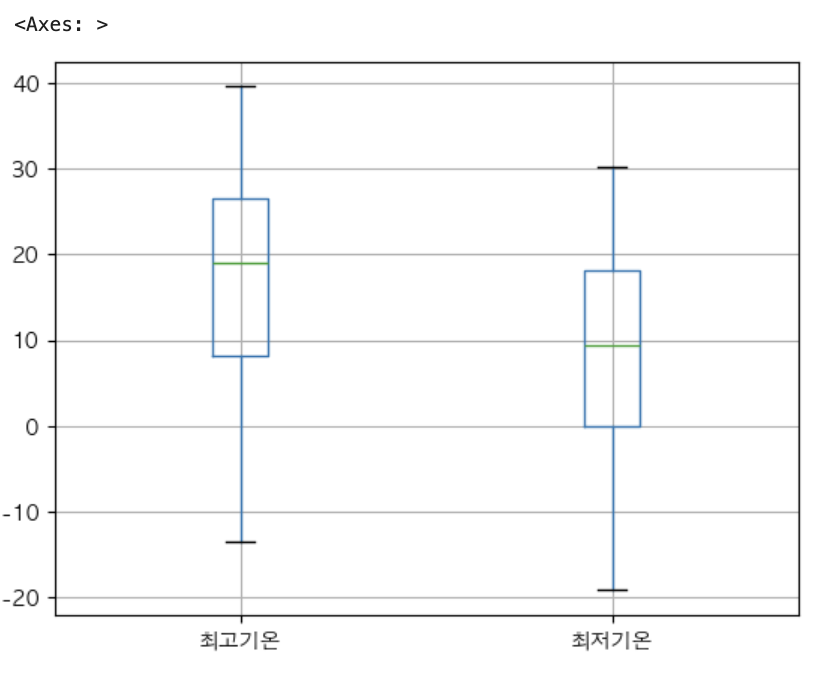
박스 플롯 - 평균과 이상치 기온 분포 비교
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('data/weather_seoul_1980to2024.csv')
df.columns = ['날짜', '지점', '평균기온', '최저기온', '최고기온']
#결측치 제거
df.dropna(inplace=True)
# 형변환
df['날짜'] = pd.to_datetime(df['날짜'])
#파생변수 생성
df['년']=df['날짜'].dt.year
df['월']=df['날짜'].dt.month
df['일']=df['날짜'].dt.day
df.head()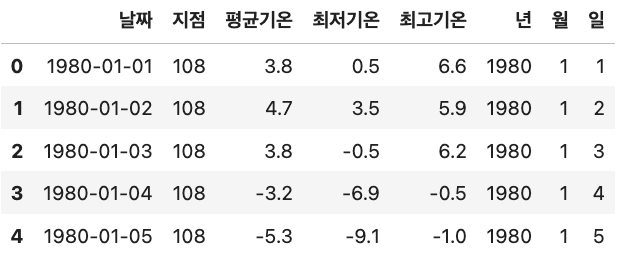
# 최고/최저 기온 boxplot 시각화
x = df['최고기온'].values
y = df['최저기온'].values
plt.boxplot([x,y])
plt.show()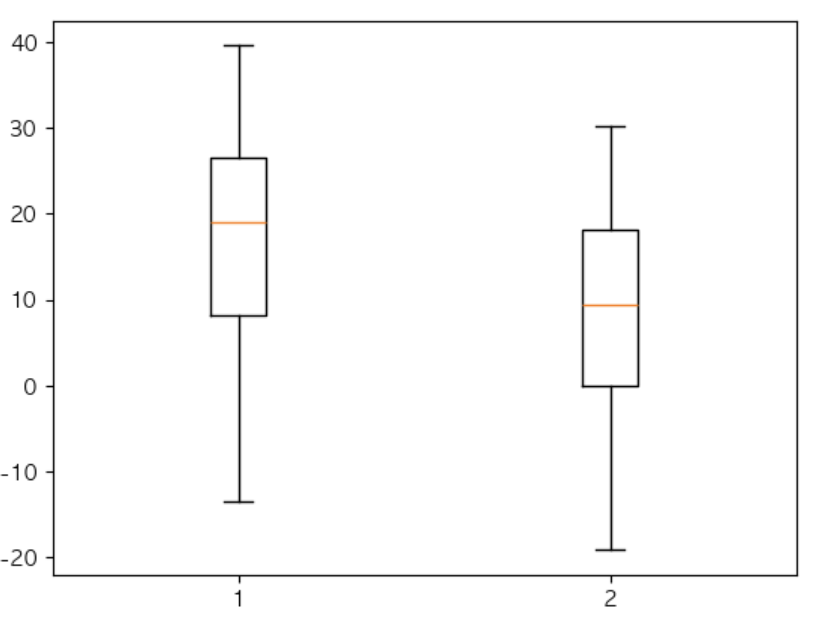
#pandas내의 boxplot() 사용
df[['최고기온','최저기온']].boxplot()
박스 플롯 - 월별 기온 분포
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 데이터 로드
df = pd.read_csv('data/weather_seoul_1980to2024.csv')
# 컬럼 이름 변경
df.columns = ['날짜', '지점', '평균기온', '최저기온', '최고기온']
#결측치 제거
df.dropna(inplace=True)
# 날짜 데이터 Str => date 형으로 변환
# df['날짜'] = pd.to_datetime(df['날짜'])
df['날짜'] = df['날짜'].astype('datetime64[ns]')
df['년'] = df['날짜'].dt.year
df['월'] = df['날짜'].dt.month
df['일'] = df['날짜'].dt.day
df.head()

cond = df['월'] == 1
cond
df[cond]['평균기온']
df.loc[cond,'평균기온']
avg_month = []
for i in range(1,13):
avg_month.append(df.loc[df['월']==i,'평균기온'])
print(i)
plt.rc('font', family='AppleGothic') #맥
plt.rcParams['axes.unicode_minus'] = False #부호
plt.figure(figsize=(8,4)) # 비율에 따른 결과 확인 할 것
plt.boxplot(avg_month)
plt.xlabel('월')
plt.ylabel('온도')
plt.title('월별 평균 온도')
plt.show()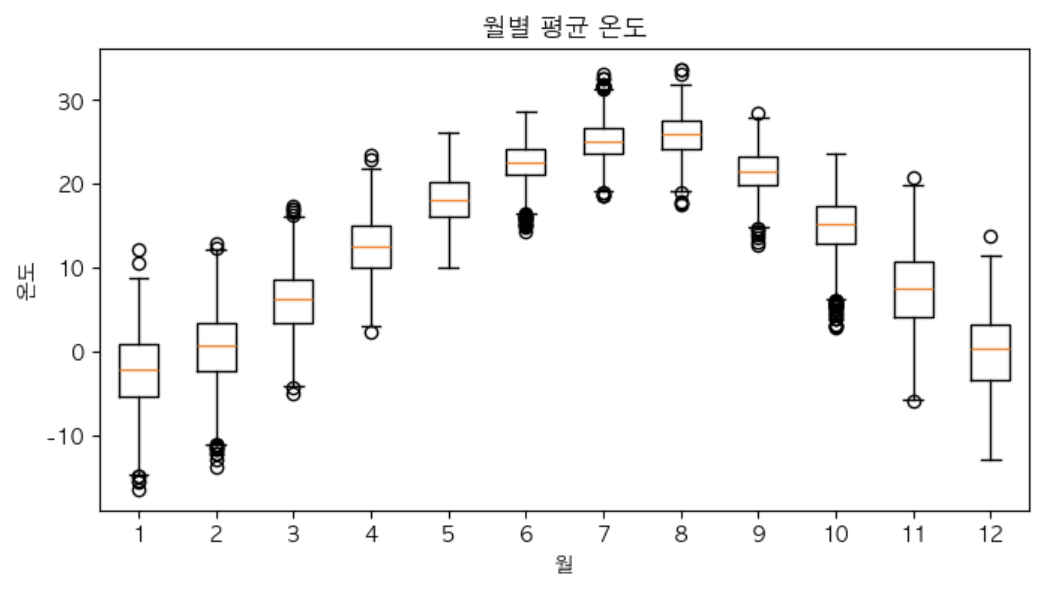
'새로워지기 > 사이드 프로젝트' 카테고리의 다른 글
| 어쩌다 휴먼 벡터 Human Vector (0) | 2024.06.15 |
|---|---|
| LET’s AI 2024 코칭 스터디 - 3주차, 팀 미션 (1) | 2024.06.11 |
| LET’s AI 2024 코칭 스터디 - 1주차, 팀 미션 (0) | 2024.05.27 |
| 시각 지능 | 신호등 신호 분류기( feat. yolo v8, roboflow 데이터 증강) (0) | 2023.10.03 |
| [from.designer] Psychology Study (0) | 2023.07.16 |




댓글